 Upgrade Storage
Upgrade StoragePDF search requires double spaces & annotations are offset (not a PDF.js issue)
I have noticed that when searching in the Zotero PDF reader, I sometimes have to input two spaces between words for the text to be detected in the PDF. When dragging with the mouse to highlight the text, there also appears to exist two spaces between the words. However, when copying or annotating the text, there is only one space. Other PDF readers find the words while only using one space to separate them (I tried PDF.js and evince).
https://s3.amazonaws.com/zotero.org/images/forums/u1905432/9x3pasqxgqv3za2klz0d.png
https://s3.amazonaws.com/zotero.org/images/forums/u1905432/yratjeqbdeu4jten0jkm.png
Interestingly, when copying the text that is highlighted in the images above, it is copied with a single space from both Zotero and PDF.js, but Zotero offsets the text with two characters, which is undesired:
Copied highlighted text from the Zotero reader screenshot
As for the text offset, this only occurs when the text contains double spaces and also effects annotations. In this screenshot, you can see how the first annotation correctly corresponds to the highlighted text (and when searching for this text, only one space is required), whereas the annotation for the text with double spaces is offset from the region that is highlighted in the PDF.
https://s3.amazonaws.com/zotero.org/images/forums/u1905432/mo0yulkm6crr9rig0kit.png
You can find the sample PDF I have used here https://drive.proton.me/urls/W1XEDD92E8#ta9U8TuOSXbS. I think this issue is quite troublesome as it can make it appear that a certain PDF does not contain a sequence of word whereas in fact it does. Any idea what is going awry here?
I'm on Zotero 6.0.35 on PopOS (Ubuntu)
Zotero's PDF Reader
Notice the double spaces in the search box:https://s3.amazonaws.com/zotero.org/images/forums/u1905432/9x3pasqxgqv3za2klz0d.png
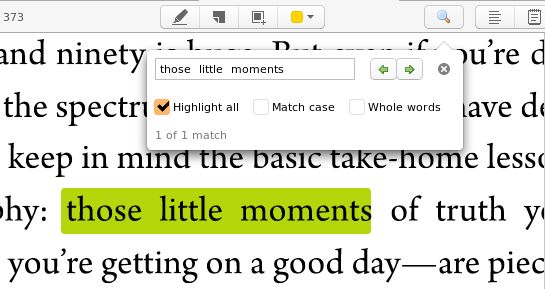{kind=link}
PDF.js
Double spaces between words are not required when searching, as expected/desired.https://s3.amazonaws.com/zotero.org/images/forums/u1905432/yratjeqbdeu4jten0jkm.png
{kind=link}
Interestingly, when copying the text that is highlighted in the images above, it is copied with a single space from both Zotero and PDF.js, but Zotero offsets the text with two characters, which is undesired:
Copied highlighted text from the Zotero reader screenshot
ose little moments of tCopied highlighted text from the PDF.js screenshot:
those little momentsThe fact that the extra space does not seem to exist when the text is copied, might suggest that this is an issue with the search functionality in the PDF reader, which might be related to the general search functionality issue with spaces posted here https://forums.zotero.org/discussion/111061/inability-of-search-function-to-detect-double-spaces/p1. Searching in the general Zotero search field (outside the PDF reader), finds the phrase regardless how many spaces are used.
As for the text offset, this only occurs when the text contains double spaces and also effects annotations. In this screenshot, you can see how the first annotation correctly corresponds to the highlighted text (and when searching for this text, only one space is required), whereas the annotation for the text with double spaces is offset from the region that is highlighted in the PDF.
https://s3.amazonaws.com/zotero.org/images/forums/u1905432/mo0yulkm6crr9rig0kit.png
{kind=link}
You can find the sample PDF I have used here https://drive.proton.me/urls/W1XEDD92E8#ta9U8TuOSXbS. I think this issue is quite troublesome as it can make it appear that a certain PDF does not contain a sequence of word whereas in fact it does. Any idea what is going awry here?
I'm on Zotero 6.0.35 on PopOS (Ubuntu)
-
martynas_b Zotero TeamThis is fixed in Zotero 7 beta. Thanks for reporting.
-
chefloThank you! I just tried it out and it works perfectly!