 Upgrade Storage
Upgrade StorageZotero OCR plugin errors
Zotero 7.0.26
Zotero OCR 0.9.2
Can anyone help explain or troubleshoot this discrepancy?
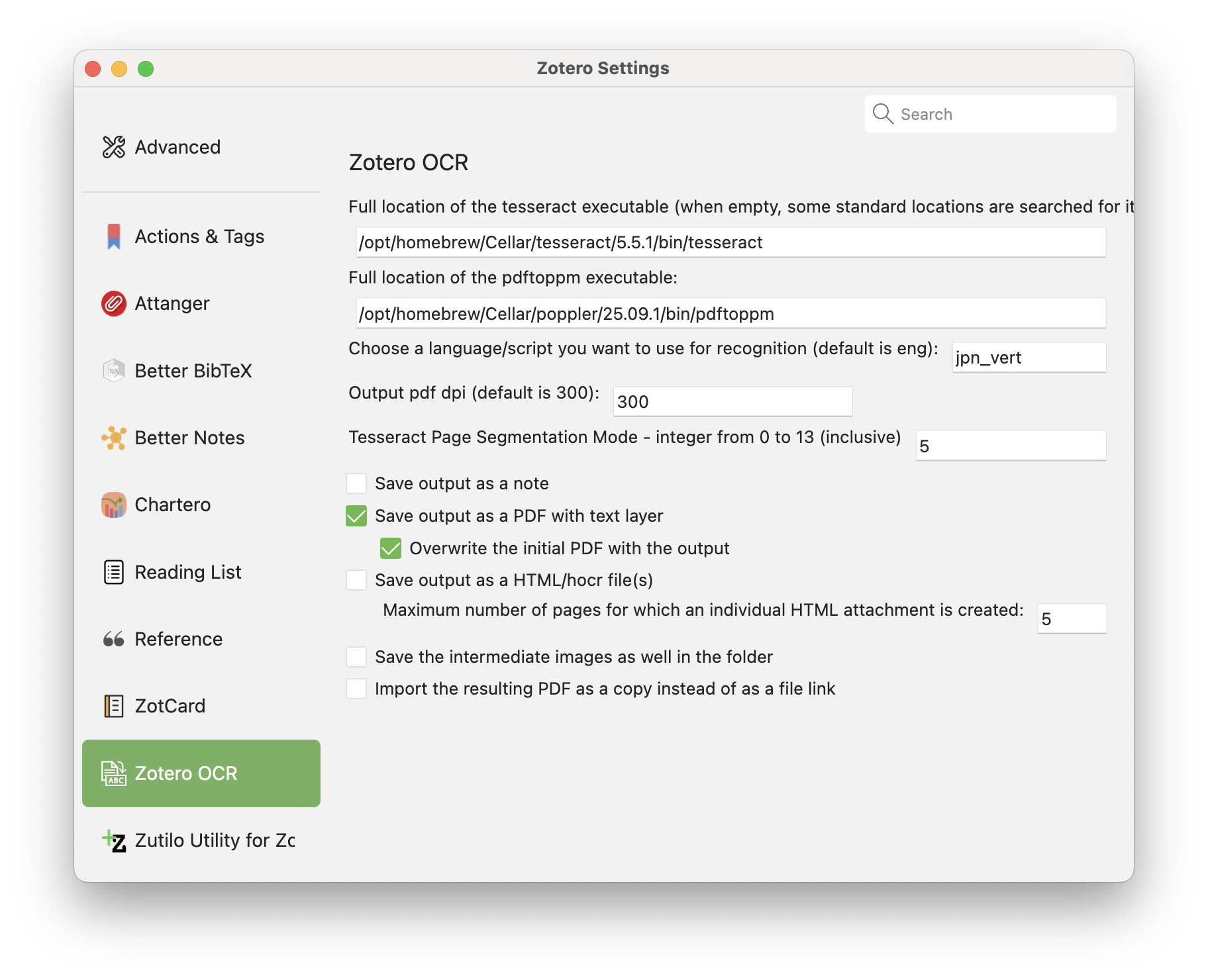
Zotero OCR settings:
https://s3.amazonaws.com/zotero.org/images/forums/u3279/tfp3610qi4k91ilswf1j.png
Results:
https://s3.amazonaws.com/zotero.org/images/forums/u3279/jr4f99fz2kmtasmftng8.png
From the plugin's GitHub, this doesn't appear to be a known issue.
(I'm posting here because it's a bigger community and has always been super helpful, but if nobody has a solution I will post there. I hope that's not bad etiquette)
Zotero OCR 0.9.2
Can anyone help explain or troubleshoot this discrepancy?
Zotero OCR settings:
https://s3.amazonaws.com/zotero.org/images/forums/u3279/tfp3610qi4k91ilswf1j.png
{kind=link}
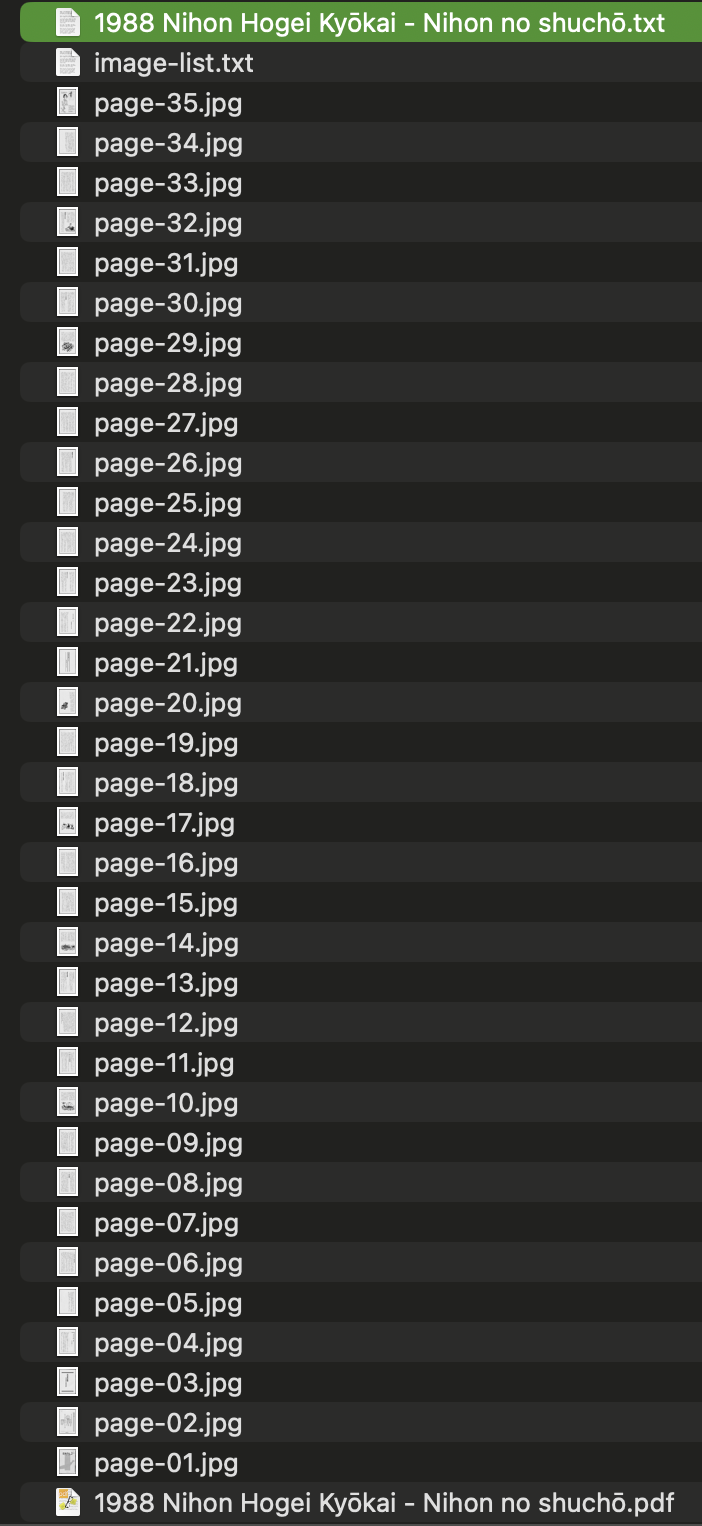
Results:
https://s3.amazonaws.com/zotero.org/images/forums/u3279/jr4f99fz2kmtasmftng8.png
{kind=link}
From the plugin's GitHub, this doesn't appear to be a known issue.
(I'm posting here because it's a bigger community and has always been super helpful, but if nobody has a solution I will post there. I hope that's not bad etiquette)
You mention a discrepancy, can you be more explicit? I can guess a few things based on the screenshots, but a description in your own words will always facilitate the discussion.
The discrepancy is that the settings and output are not matched up.
I have unchecked "Save output as note" and "Save the intermediate images" but they are output anyway.
In the interim, I have additionally noticed:
1. The resulting PDF balloons in size, from 19MB to 650 in the case of one 55-page B/W scan, for instance. Makes Zotero super heavy, takes forever to open, etc.
2. The text layer is nonsense machine text when viewed in some PDF viewers but not others. Acrobat and Preview render correctly, but Skim gives me a lot of 蝗ス髫帶黒魃ィ蟋泌藤莨. Don't know if that's relevant, but this is related to the issue that caused me to install the plugin to begin with: Acrobat (fully updated) newly gives that junk machine text for many Japanese files, which I assume is a font embedding issue but can't be certain.
In any case, I assume 1 and 2 are Tesseract issues, not Zotero OCR issues, but they make the plugin basically unusable for me unless there's a workaround.
Does this happen only with this file, or do you have other Japanese PDFs where similar problems happen? Can you share a file that could be used for tests?
The file size and garbage text was new yesterday with every PDF I tried. This was true for both PDFs directly downloaded from Japan's national library (NDL) -- flattened or not -- and also for PDFs compiled from scanned images (TIFF).
Here's the file that blew up to 650MB:
*deleted*
Thanks for you help!
Another file might probably work just as well for testing, but I'd like to be sure we agree on the same file.
That was very strange! Dropbox killed my link sharing for several hours and then the link was corrupted. I don't know what happened, but I tested the link below and it should lead to the right file:
https://www.dropbox.com/scl/fi/b375aes9hdol0voas3r3m/icr2-flat.pdf?rlkey=ki50ncjwkf57qoe2rdn609lvy&dl=0
- OCR result: I can't read Japanese so I'm not the best judge, but overall I don't see a general problem with the file you provided. In some pages the text layer certainly has errors, some others look OK in my untrained eye. If a specific PDF reader has a problem with the file, maybe it should be reported there? If you can point out a specific page that exemplifies this problem, I can take a closer look, of course.
- file size: this is certainly a weakness in Zotero-OCR, but for me it wasn't quite as bad as you report. My OCRed PDF was 217MB, not 650? Looking at the original PDF, I'd say that it was produced with a 150 to 200 DPI resolution. You can try 150 instead of 300 in your preferences: the output PDF will be larger than the original one, but far less than with the default of 300, and the apparent quality should not be affected. In my test at 150, the OCRed PDF is 80MB.
- I see the Attanger plugin in your Zotero preferences, are you using Zotero-OCR on linked files managed by Attanger?
- have you OCRed several files that are stored in the same folder?
- did you first try to use the plugin with the note and images options activated?
- are the residual images (and image-list.txt) perhaps older files that were generated in one of you first tests?
I would also recommend trying again with the new Zotero-OCR 0.9.3 release. We have introduced several features that will tell you more about the execution of the plugin, and make diagnostics much easier.
First, I'm now on 0.9.3 and the issue with PNGs is gone. The garbage system character (文字化け) issue seems improved, but I'm using the plugin much less right now.
To answer your questions:
- Yes, but only after I've verified their on my HDD, not just linked in the cloud
- Yes
- No
- No