 Upgrade Storage
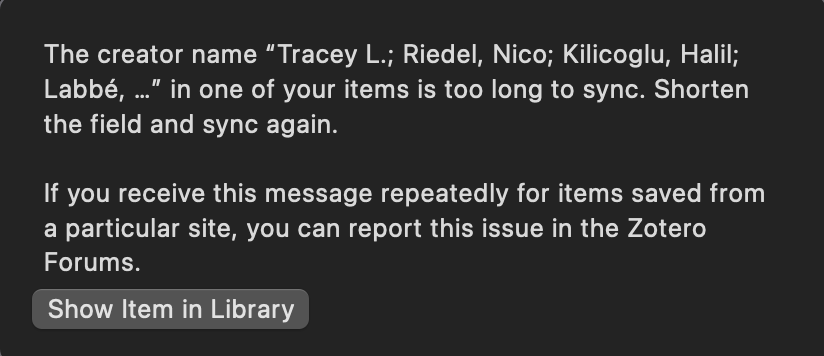
Upgrade StorageSync Error: Long author list for countless papers
I have an issue with long author lists for many papers in multiple Zotero folders. Manually sorting through the author fields would take a great deal of time.
Does anyone know a way to automate/circumvent the syncing problem of papers that have many authors?
https://s3.amazonaws.com/zotero.org/images/forums/u5604797/yjdzspxguaarhh4p5j46.png
I realize this is an old error to mention on this forum, but it seems so important that I can't believe it hasn't been correct thus far.
https://forums.zotero.org/discussion/comment/280209#Comment_280209
Does anyone know a way to automate/circumvent the syncing problem of papers that have many authors?
https://s3.amazonaws.com/zotero.org/images/forums/u5604797/yjdzspxguaarhh4p5j46.png
{kind=link}
I realize this is an old error to mention on this forum, but it seems so important that I can't believe it hasn't been correct thus far.
https://forums.zotero.org/discussion/comment/280209#Comment_280209
Where did you import this data from, and how exactly did you import it? E.g., saving that item from PubMed via the Zotero Connector imports the authors properly.
I've been doing so for years, but lately the multi-author papers are more common in my discipline.
For now, I'll manually sort through the poorly imported documents and maybe code up an extension to flag the bad ones. If there was a way to alert users during and after import (immediately), that would help.
I don't use OVID much these days and occasionally use PubMed.
More often, I download preprints and straight from journal article webpages.
What are the values of the URL and Library Catalog fields?
On MacOS, using Zotero 7:
Article 1
URL: https://arxiv.org/abs/2406.16253
Library Catalog: missing, no text shown here
https://s3.amazonaws.com/zotero.org/images/forums/u5604797/6cqfeop5bfibdg5fzd3f.png
Zotero does have a tool that lets you split or delete long tags that were incorrectly concatenated in exported data, and it automatically shows that tool on sync when necessary. We should probably add a similar feature for creators, and extend it to run on multiple items. That's probably the best we can do.
For your current situation, I've provided a script for people that just removes long creator entries, but that was in the case of Ovid where, as I say above, it was just junk data. These look like valid authors, so you wouldn't want to do that. If you have a lot of these, someone (or you) could adjust that script to convert these to separate creators. Alternatively, if you haven't done anything with these items yet, the easiest option would be to just sort by Date Added, delete the entire batch of items with invalid creators, fix the file you imported with Find/Replace, and reimport.
I am not sure what this means. If I click the Zotero Connector (Chrome extension) in my browser and find that the metadata and PDF are copied over to my Zotero account, is that not using the Zotero Connector?
For my fix, I'll play with scripting a special solution using some kind of LLM.
You get the same if you get the PDF directly from your browser (that's not always the case, but it is here).
If I had to guess, this looks like bad RIS from somewhere. The arXiv (Cornell University) is particularly odd -- that's not how arXiv brands itself.
My hypothesis is that the bad RIS issue may be due to me using the Zotero Connector extension when I visit the Google Scholar page for a given preprint or article. I have found that doing so is sometimes needed to import PDFs. So that's something I can stop myself from doing in future if it's the root issue.
I didn't even think about that.
Again, the Zotero Connector save button would not produce the data in your screenshot under any circumstances.
Saving that item from Google Scholar via the Zotero Connector results in high-quality metadata from arXiv, with "arXiv.org" in the Library Catalog field, and a PDF.
(Just exporting RIS ("RefMan") from Google Scholar and letting the Zotero Connector import it results in much worse metadata, with nothing in Library Catalog, but it still imports individual creators without this problem.)
https://s3.amazonaws.com/zotero.org/images/forums/u5604797/0ibkhb5939bd5l44gkyb.png