 Upgrade Storage
Upgrade StorageZotero collects Snapshot only, not full PDF
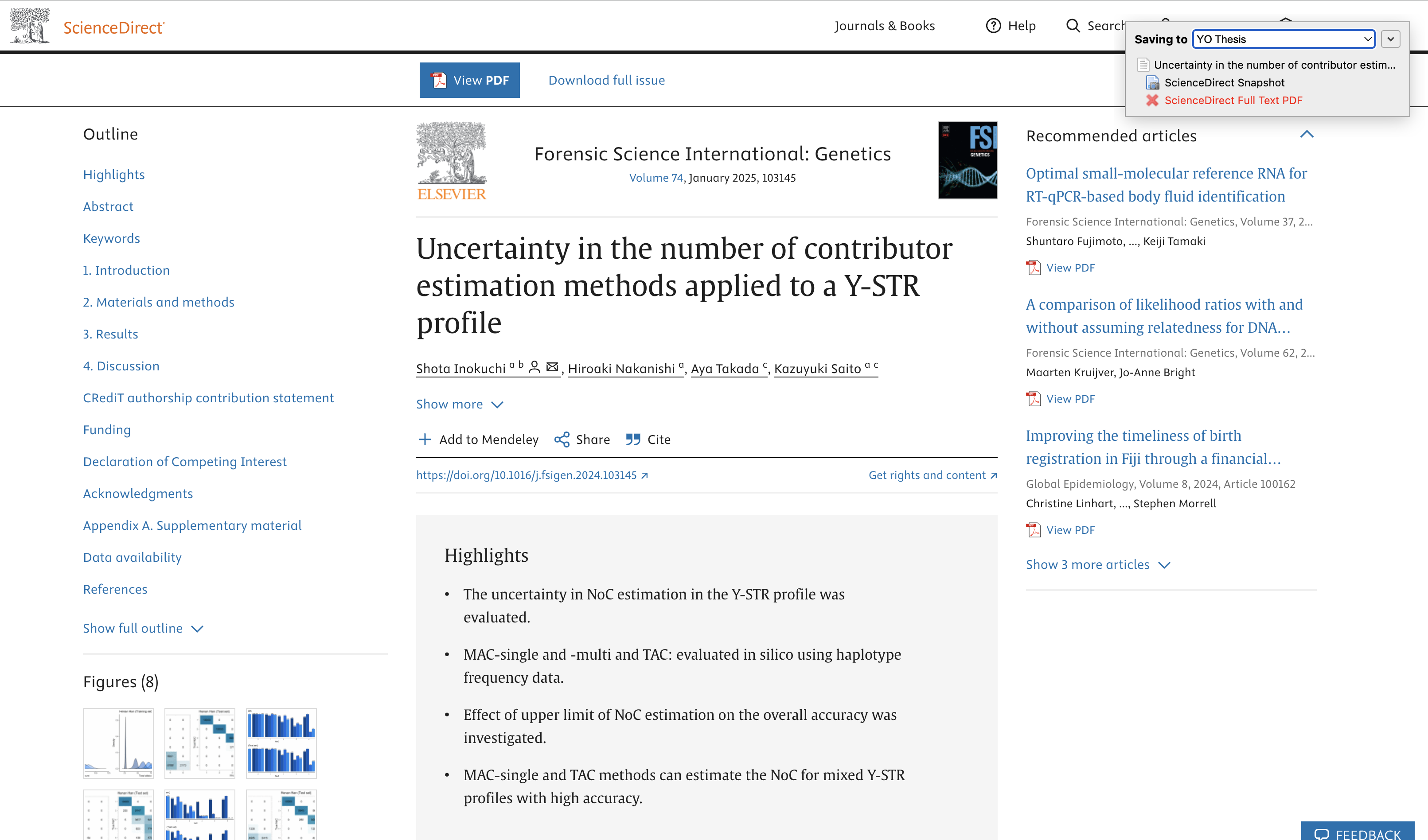
I have uninstalled and reinstalled Zotero. It's the updated version. I'm on a Mac (Sequoia 15.0) using Chrome (up to date).
I'm logged in to my university library so I can access full pdf articles. But can't seem to get Zotero to save the full pdf. I can open the pdf and save that, but then it doesn't have all the same information automatically pulled, only some of it.
https://s3.amazonaws.com/zotero.org/images/forums/u15076694/9yf1j2g31xcmu1p2gh8j.png
Any ideas why this won't work? Thank you
I'm logged in to my university library so I can access full pdf articles. But can't seem to get Zotero to save the full pdf. I can open the pdf and save that, but then it doesn't have all the same information automatically pulled, only some of it.
https://s3.amazonaws.com/zotero.org/images/forums/u15076694/9yf1j2g31xcmu1p2gh8j.png
{kind=link}
Any ideas why this won't work? Thank you
https://forums.zotero.org/discussion/109940/zotero-is-not-saving-pdfs-from-sciencedirect#latest
But the validation windows do not appear anymore.
I am seeing this also from yesterday. I have also tried from home and see the same problem.
URL: https://www.sciencedirect.com/science/article/pii/S0021850223001787
Zotero Connector - Debug ID: D1892424967
Zotero Desktop - Debug ID: D755254984
Also cannot get the PDF from the PDF page directly:
Zotero Connector - Debug ID: D1452394090
Zotero Desktop - Debug ID: D1693323906
Zotero 7.0.7-beta.3+20d13f5a8 (64-bit)
Windows 10
Zotero Connector - Debug ID: D1807147090
Zotero Desktop - Debug ID: D2050525247
Curiously, when I try to use a proxy, it downloads a PDF file, of size 47 Ko, which is not a valid file.
Zotero Connector - Debug ID: D249656681 / D1995790426
Zotero Desktop - Debug ID: D1413065696
https://s3.amazonaws.com/zotero.org/images/forums/u265723/92iosg22unjvqy72ljqp.png
https://s3.amazonaws.com/zotero.org/images/forums/u265723/82nau0kf0dgjecqj5art.png
https://www.sciencedirect.com/science/article/pii/S0021850223001787
Yes, I can load the PDF file in the browser from the unproxied URL.
It works either when I am logged in:
https://s3.amazonaws.com/zotero.org/images/forums/u265723/5jtdttd1piqnxawwkgsa.png
Or logged out and removed all cookies:
https://s3.amazonaws.com/zotero.org/images/forums/u265723/1mqdvyn5pp5hpr3lu6hh.png
I am just using the normal university access to the full text PDF.
From the unproxied PDF file page in the browser, I cannot import the PDF file to Zotero:
https://s3.amazonaws.com/zotero.org/images/forums/u265723/xug5z8d40tjq83mm2q8z.png
When using the proxy, the PDF file also loads correctly in the browser.
From the proxied PDF file page in the browser, I can import the PDF file to Zotero:
https://s3.amazonaws.com/zotero.org/images/forums/u265723/kijp0nthbbiekjgfhcb9.png
The correct PDF file is saved in this case, contrary to the invalid file downloaded from the article page.
For PDFs that cannot be downloaded, there is at some point (after a few tries) a page with a CAPTCHA popping up. If you click it then you can download again.
But this CAPTCHA page does not appear each time a PDF cannot be downloaded.