 Upgrade Storage
Upgrade StorageZotero automatically dividing PDFs into "parts"?
Hi all!
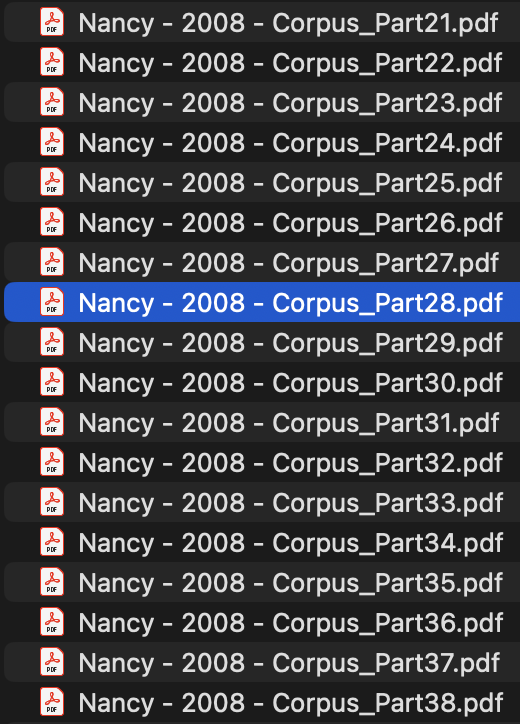
I just noticed this (potential?) problem a few seconds ago, so I apologize in advance for not being more precise or clear. I was looking through my PDFs on my computer and I saw that one of my PDFs for "Corpus" was divided into some 47 parts. Each of these parts are stored in the same Zotero internal library folder (Zotero > storage > ###). And when I open the PDF entry in my library I just see one PDF that is complete and without parts. It seems that in the same internal folder there is one PDF that is the whole text, but then this doesn't explain why there are so many parts.
Is this normal? I am surprised I haven't noticed this before. I am interested in this because I care about file management and having so many different parts produces clutter.
Attached is a screenshot of some of the different parts that were generated.
Any guidance or help would be appreciated! Thanks!!
https://s3.amazonaws.com/zotero.org/images/forums/u1815503/hitywuncg9mnt3786lo2.png
I just noticed this (potential?) problem a few seconds ago, so I apologize in advance for not being more precise or clear. I was looking through my PDFs on my computer and I saw that one of my PDFs for "Corpus" was divided into some 47 parts. Each of these parts are stored in the same Zotero internal library folder (Zotero > storage > ###). And when I open the PDF entry in my library I just see one PDF that is complete and without parts. It seems that in the same internal folder there is one PDF that is the whole text, but then this doesn't explain why there are so many parts.
Is this normal? I am surprised I haven't noticed this before. I am interested in this because I care about file management and having so many different parts produces clutter.
Attached is a screenshot of some of the different parts that were generated.
Any guidance or help would be appreciated! Thanks!!
https://s3.amazonaws.com/zotero.org/images/forums/u1815503/hitywuncg9mnt3786lo2.png
{kind=link}
This doesn't feel like standard Zotero behavior. Do you see this with other PDFs? Did you do something special with this one recently? Are you using plugins, and if yes which ones?
@aborel – It seems like it is only this document. I don't think I did anything interesting – I will check the document history, but it is possible I use OCR tools on this... maybe it was that? I will test this now. And no, I do not use any plugins.
@samvimes - I did not download it from the webpage, the document I downloaded was complete.
1. Deleting the files (the parts, not the whole) changed nothing. So it was stored in the document library but not connected to the entry (which is its own curiosity).
2. My running hypothesis now is that one of Adobe's OCR either splits up the document or I might have done so by accident. This would be the relevant "tool."
https://s3.amazonaws.com/zotero.org/images/forums/u1815503/jxk3ek09yjr23mdcvuhf.png
Maybe this is the issue? I will continue testing.
The point of my link was to provide a reference to what would be considered as excessive impatience. If you read that page, I'm sure you'll find you were completely within the accepted boundaries :-) Perhaps I should have added a few words to explain that right away.
Anyway, I hope this was indeed a one-time problem, but if it happens again don't hesitate to ask for assistance again! It might take a couple of days before someone answers, but someone will, for sure.